
2018年8月15日,光环影响力·产品经理修炼之道全球直播系列大课第三期由猎聘的石晶老师带来“数据分析”主题,本文为讲座的精彩回顾。

我们生活在一个“大数据”的时代,大家都希望从数据中间挖到“真金”,利用数据实现用户的增长,提高运营效率。很多人说我们只相信数据,因为只有数据是客观的。这句话有一定道理,但如果我们不知道数据背后的逻辑,最后仍然可能掉入数据的陷阱。
不相信的同学,可以来试试下面这个直觉的小测试:
我们都知道产品经理为了获得用户的信息,经常会去开展用户调研。比如我曾经做过一个针对某某产品的满意度调研,调研的用户被分为A、B两组。A组男性的满意率是60%,女性满意率是70%,那么大家能看到男性满意率比女性满意率低10%。在B组,男性满意率是20%,女性满意率是30%,男性满意率比女性的也低10%。那么整体而言,男性满意率低于女性满意率,是这样吗?

听上去这是一个理所当然的结论,但最后的结果却不一定。大家看一下背后的数据:
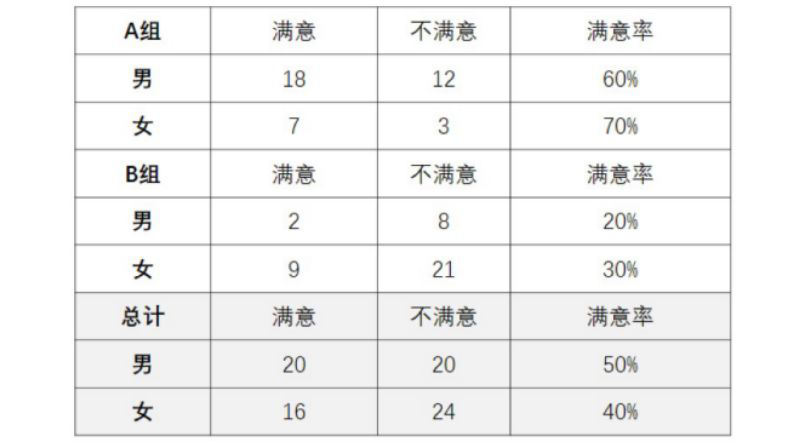
大家可以看到,A组和B组里的男女满意率数据和之前确实是一致的。但当我们把A、B两组的数据加在一起,男性的满意率居然比女性要高?
这件事情就细思极恐啦。在整个人群里,男性的满意度比女性要高,但若我们进行抽样,我们仍可以得到结论男性的满意度比女性低。这就是统计学上非常著名的辛普森悖论。也就是说这样一个其实比较好理解的事实,我们若通过直觉来判断,即使借住数据的帮助也仍然会出错。
这里还有另外一个例子:吸烟与肺癌的关系。如果我们从历史数据上观察,可以观察到吸烟的人更容易得肺癌,所以吸烟和肺癌是正相关。但是我们可以说是吸烟导致肺癌吗?其实这个事情是很难说的。因为可能存在一些未观测的因素,既影响个体是否吸烟,同时影响个体是否得癌症。有这样基因的人即使不吸烟,也容易得肺癌。这时我们只能说吸烟和肺癌有相关性。
我们再看一个例子:了解二战的人都知道,在二战中,参加空战的飞机很容易受损、坠机。于是美国空军做了研究,统计那些从战场上安全返回的飞机的着弹点,看飞机受伤的地方主要分布在哪里,从而在今后制造飞机时加固这些部位。这时候有个统计学家指出这个统计是不对的,因为只统计了从战场上安全返回的飞机,那些被击落的飞机根本没有参与统计。这就是统计学上非常著名的“幸存者偏差”概念。

我举了3个例子。第一个例子中,我们使用定性研究的方法,试图用数据得出结论;第二个例子中,我们使用数据研究相关关系;第三个例子中,我们收集数据作统计分布研究。在三个例子中我们都使用了数据,却都容易陷入细节的陷阱中得出错误的结论。所以光有数据不一定能得到正确的结论。
对于产品经理来说,该怎么办呢?
内功心法:玄门正宗
我的建议是我们要苦练内功,把内功练好,犯错的概率就很低。内功也有很多类型,有的是玄门正宗的内功,在练习的时候进度比较慢,但是根基特别扎实;如果一开始贪图速度快,去学旁门左道的内容,那么到了后期你犯错的概率就会高。
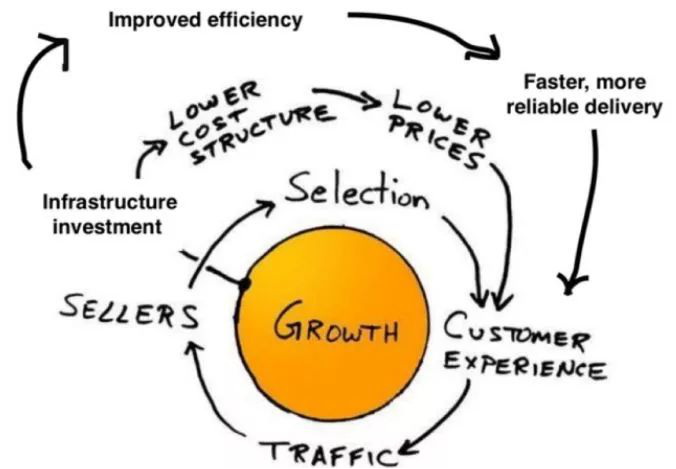
在数据分析里,我认为分析体系是整个的核心。说到玄门正宗的内功,我们很容易就想到电商的泰山北斗——亚马逊。关于亚马逊的传说有很多,但其实你若和亚马逊的人聊天,你会发现他们推崇的不是那些花哨的招数,而是亚马逊的“三个飞轮”:
o当我把所有商家聚集到一起,用户就有更多选择,就会产生更好的用户体验,从而带来更多流量;
o如果我们进一步降低成本的结构,让用户享受到更低成本的服务,我们又可以获得更多流量。
o如果我们进一步提高效率,让大家享受到更好的送货和交付服务,那我们就可以得到在之前基础上更好的流量。
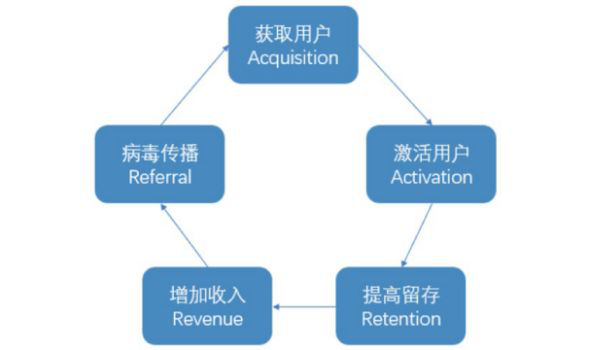
我们可以说,分析体系就是数据分析中的到“道”,它的表达一定是很简洁的。在互联网的用户增长中间有一个著名的AARR模型,如下图:
凡是这种比较靠谱的、玄门正宗的分析体系,它的形式都很简洁,但内涵是很丰富的。比如我们拿出AARR模型中的获取用户环节进行漏斗拆解,就可以得到下面这样的结果:
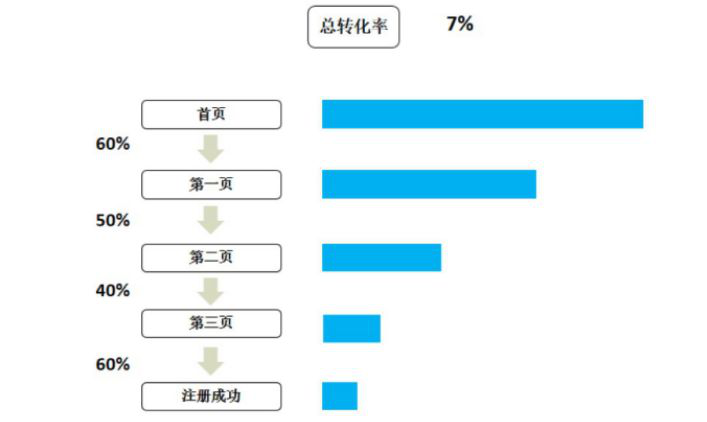
分体体系不光可以把每个环节进行拆解,还可以把不同的环节进行打通。比如我们刚才提到的用户获取环节,一般只关注到用户获取,没有关注到用户的商业价值。如果可以将它和用户激活、留存联系起来,我们就可以形成一个更加全面的、从商业价值角度来考察用户获取渠道的图,如下例:
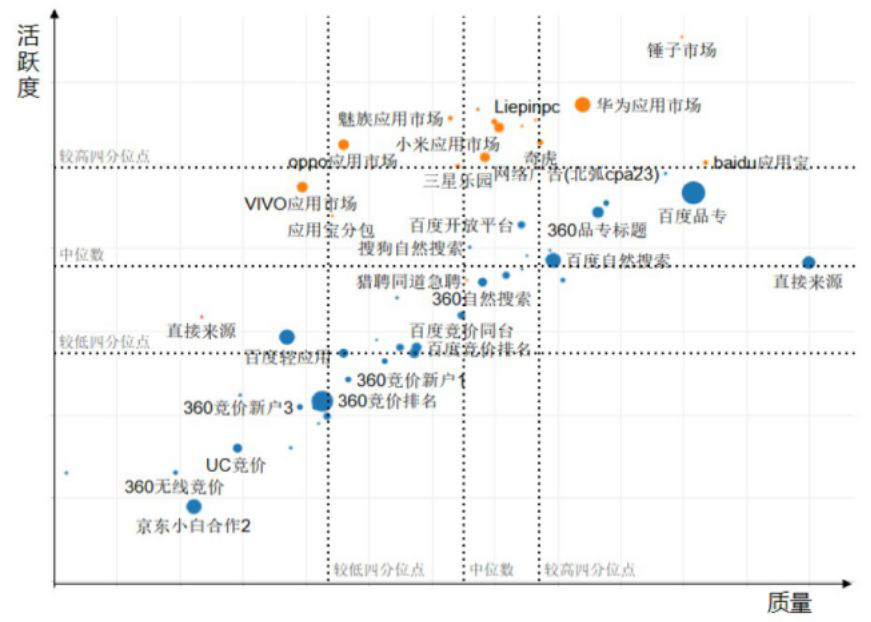
该图是猎聘的真实例子。以在线招聘业务为例,我们希望获取的用户质量高、简历佳,也希望用户主动看职位来应聘,于是我们从用户的质量和活跃度两个角度一起来看,关联到用户的商业价值,而不是只简单的看用户量。
招式:重剑无锋
数据分析的招式是千变万化的,只要内功练好了,招式就非常容易出效果。在射雕英雄传里,有一个情节让我记忆深刻。郭靖在刚刚学降龙十八掌的时候,只学了内功,招式来不及学全,只会一招“亢龙有悔”,这时候他的仇家寻上门来了,郭靖只好用一招御敌,但由于他的内功修得非常到位,所以这个简单的招式发挥了非常大的效果。
在整个招数里,我比较推崇的是在练好内功(分析体系)之后,可以用非常简单的招式来应对。在这里我推荐一个非常适合初学者使用的、效果很好的招式:
建立假设、小心验证
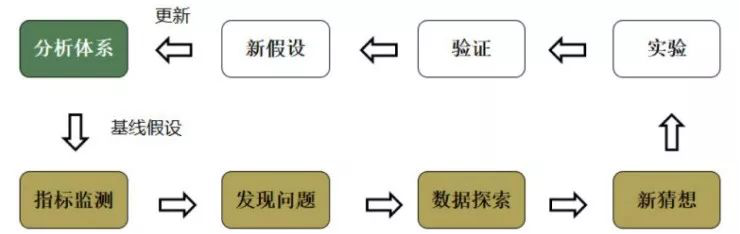
在有了分析体系之后,其实我们也有了一个“基线假设”。什么是基线假设呢?比如我们刚才如果使用用户获取的漏斗,那么这个漏斗的合理转化率是多少就是基线假设。在有了基线假设之后,我们在进行指标监测的时候对指标的范围就能够做到心里有数。
比如我们在分析的时候发现,用户已经点击付款了,但完成付款的转化率只有50%,那我们就会知道可能是产品有问题,或者数据统计出了错误。围绕问题我们可以进行数据探索。这其中最有价值的点在于通过数据的探索,可以发现原有的分析体系的不完备之处,这时其实是数据发挥最大价值的时候。
基于新的数据探索,我们还可以有一些大胆的新猜想,但在猜想之后还要用数据进行验证,不光是做历史数据的验证,还要进行新的实验(如A/B测试、AA测试等)进行验证。在通过验证之后得到的新假设,可以用于更新原有的分析体系,建立新的基线假设,在此基础上又可以展开新一轮的指标监测,发现新的问题。
这个招式其实看上去就一招,就是建立假设、小心验证,如此循环往复。但事实证明,这个方法是非常有用的,相比从一开始就脱离体系,去单点地找问题,它发挥作用的可能性要高得多。
我在刚到猎聘的时候 ,与C端用户的产品经理聊,发现当时有一个情况就是大家对于用户的行为有下面这样的假设:
用户访问猎聘网站的频率和周期和用户的求职周期是完全一致的,比如:一个人平均2-3年换一次工作,所以用户也会2-3年会来一次招聘网站;在互联网行业,找工作一般是1-2个月,所以我们认为活跃期一般为30天;在整个活跃期中,用户平均访问网站次数为10次。
那么这个假设对不对呢?我当时觉得这个假设还是挺靠谱的。因为它和我们实际工作中的经验比较吻合,这个假设也和当时的一些数据非常吻合。
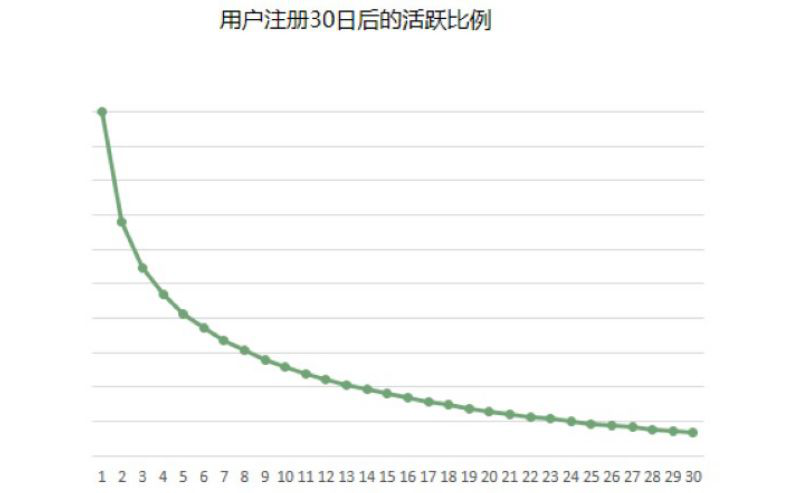
我们当时看了2个数据,一个是用户注册30天后的活跃比例(下图),比如第一天有100个用户来了,第二天可能就再访问网站的只有70个,第三天更少,这样逐步减少到0。我们当时觉得一个用户的活跃周期是30天是基本合理的。
另一个数据是注册用户数与网站日活数进行对比(下图),这两条曲线趋势惊人的一致。
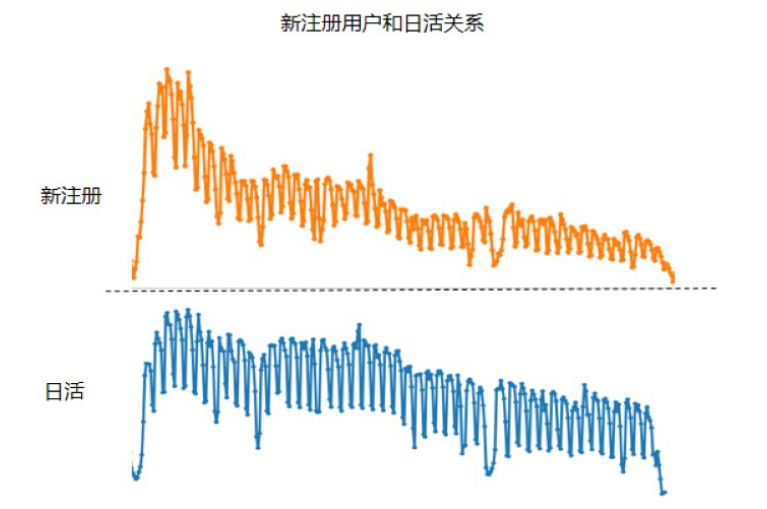
由于这些数据非常完美,我们认为我们已经掌握了用户的行为规律。但是所有的数据之间能互相验证的时候,往往也是非常危险的。果不其然,我们刚才举例的时候说的是第一个用户活跃周期,那么到了第二个用户活跃周期的时候,曲线就发生了变化。橙色线显示,新注册用户数在第二个大周期比第一个周期有所下降(因当时广告投放的成本控制所致),但是用户的活跃(蓝色线)并没有受此影响,而是显著上升的。也就是说,用户访问频率和求职周期并不相符。这就与前面的假设相矛盾了。那么原先的假设是哪里出现问题了呢?
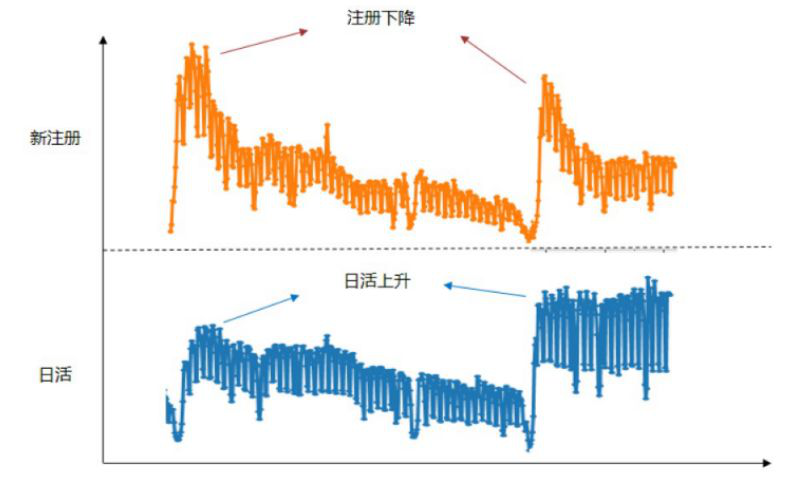
很多时候出现问题对于数据分析师来说是一件好事,因为问题的出现往往也是数据分析的提升机会。后来我们对数据进行深入分析发现,原先基于直观经验和简单调研而对用户进行的假设,是不能够刻画所有用户的。事实上,只有大概50%多的用户是和我们的假想一致的,而小一半的用户则不然,有些用户甚至一年之中有10-12个月都会来访问招聘网站。
工具:唯快不破
数据分析要慢工出细活,要把基础打好。但是在工具方面,就一定要唯快不破了,我们要追求效率。
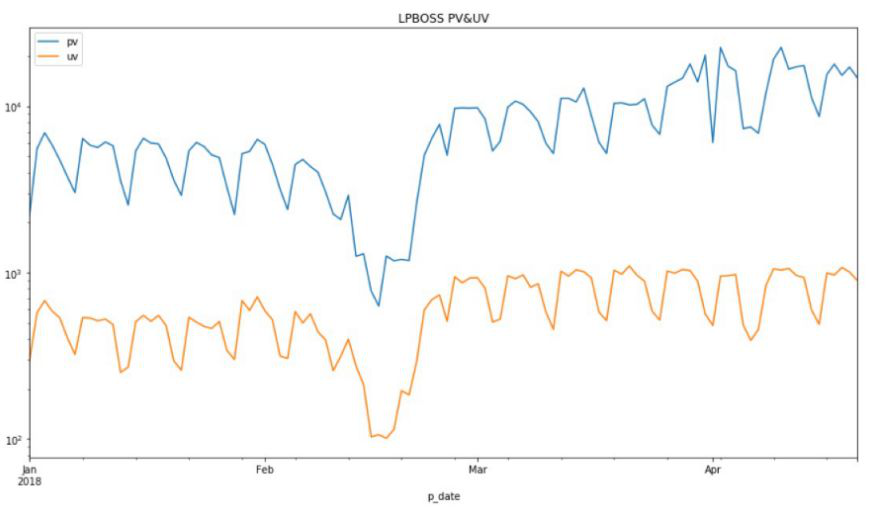
在当今时代,数据是最宝贵的资产,所以对于能够爬取网站数据的爬虫我们应当加以关注。那么应该怎样分析网站数据中是否有爬虫存在呢?比如说我们抓取了网站的UV和PV数据,直观上觉得有爬虫的时候,UV和PV的关系一定是有异常的。但是比如下面这张图中,要找出UV和PV异常的点,是比较困难的。
但是同样的数据,如果我们从不同尺度进行探索,就会有明显的差别:
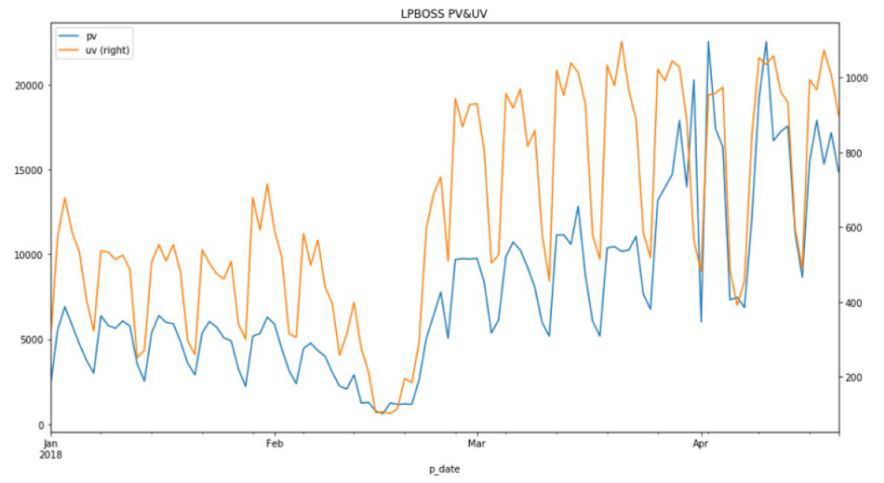
即使是这样,我们仍然半信半疑,这些异常真的是否表明有爬虫呢?这时候我们可以再做进一步的数据探索:按小时进行观察比对。
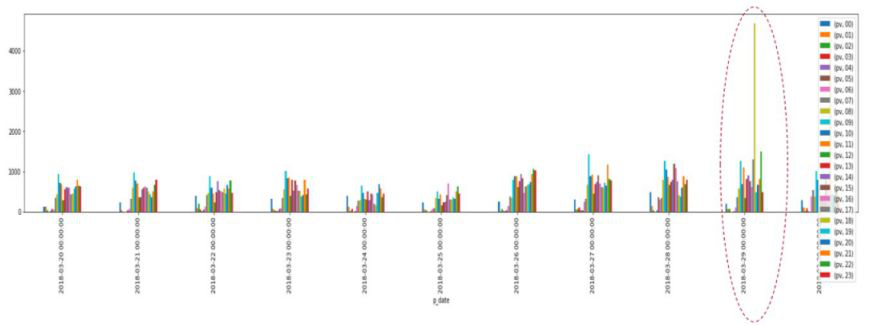
如下图,每一根柱子代表一个小时的访问量,可以很明显地看到右侧一根黄色的柱子显示很明显,这种数据一定是有异常波动的,很可能是有一个爬虫程序在访问网站。
当我们有一个业务猜想的时候,进行探索的量可能是很大的,这时候整个探索的效率就显得很重要。对产品经理来说,一定要学会EXCEL中的透视表等工具,以及掌握一些可视化的方法。
困惑和迷思
最后我还希望与大家分享一下数据分析中常见的三个困惑。
脱离决策看数据:丧失焦点,劳而无功
我在工作中会招聘很多数据分析师,在面试的时候,我特别喜欢问一个问题:你觉得你做数据分析是为了什么?
很多人告诉我,是为了从数据中发现规律的时候的那份快乐。
这句话是没错的。但我们生活在一个数据维度爆炸的时代,在做产品相关的数据分析时,不可能把所有维度、所有问题看得那么清楚。我们做数据分析的目的是为了在研究产品的时候把重点问题找出来,排序工作的优先级,而不是搞清楚所有问题。所以我们要探索数据,但不能脱离决策去探索。
是否决策越多越快越好?
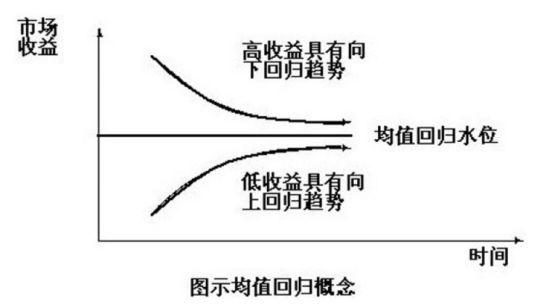
在投资领域,有一个叫作“均值回归”的概念,即当一个投资组合具有很高收益的时候,它其实也具有向下回归的趋势,即回归于平庸,反之亦然;短时间看,投资收益有高有低,但最后大家都会变得差不多。
我们在做数据分析的时候情况也是一样的。虽然我们有时候看到数据在波动,但很多波动是随机的、暂时的,并不能说按天决策、按小时决策就一定比按周决策、按月决策要好。
我们的系统是由暂态和稳态组成的,当系统处于暂态的时候,对系统施加控制往往无法达到预期,而当系统处于稳态的时候再施加控制则可能会很快达到预期。所以我们建立指标分析体系是很重要的,会有利于帮助我们判断系统是否处于临时的波动状态,如果是,则不要轻易地做运营决策,最好能等趋势比较明显和稳定之后再来决策。
公关故事中的Tricks怎么学?
现在是一个信息爆炸的时代,我相信大家从各个渠道都关注了大量的先进企业的先进经验和技巧,我们当然要学,但不用每一个都学。当我们看到炫目的技巧时,应当考虑2个问题。
首先是事件的背景是什么。很多时候网上的文章为了获得点击量只会摘取最吸引眼球的部分公布,而背后的背景则不太愿意讲。而企业的决策和其当时的背景是有很大联系的,我们应当要把决策背后的原因找出来。
第二则是我们要与故事背后的人、相关企业的员工进行沟通,从而决策我们是否真的要学习。
我们所有人都生活在大数据的时代,人人都想从数据中挖到金子,但是数据分析的道路是充满陷阱的。为了把数据分析做好,一方面要苦练内功,学习一些朴实无华的数据分析招式,同时拓展自己使用数据分析工具的能力,让数据探索更快,效率更高。
在未来,数据分析会成为产品经理必不可少的技能。无论大家现在是运营岗位还是从事产品设计,如果在数据分析上有一定基础,一定可以在让产品经理的道路越走越宽,越走越远。
2018年8月15日,光环影响力·产品经理修炼之道全球直播系列大课第三期由猎聘的石晶老师带来“数据分析”主题,本文为讲座的精彩回顾。
我们生活在一个“大数据”的时代,大家都希望从数据中间挖到“真金”,利用数据实现用户的增长,提高运营效率。很多人说我们只相信数据,因为只有数据是客观的。这句话有一定道理,但如果我们不知道数据背后的逻辑,最后仍然可能掉入数据的陷阱。
不相信的同学,可以来试试下面这个直觉的小测试:
我们都知道产品经理为了获得用户的信息,经常会去开展用户调研。比如我曾经做过一个针对某某产品的满意度调研,调研的用户被分为A、B两组。A组男性的满意率是60%,女性满意率是70%,那么大家能看到男性满意率比女性满意率低10%。在B组,男性满意率是20%,女性满意率是30%,男性满意率比女性的也低10%。那么整体而言,男性满意率低于女性满意率,是这样吗?
听上去这是一个理所当然的结论,但最后的结果却不一定。大家看一下背后的数据:
大家可以看到,A组和B组里的男女满意率数据和之前确实是一致的。但当我们把A、B两组的数据加在一起,男性的满意率居然比女性要高?
这件事情就细思极恐啦。在整个人群里,男性的满意度比女性要高,但若我们进行抽样,我们仍可以得到结论男性的满意度比女性低。这就是统计学上非常著名的辛普森悖论。也就是说这样一个其实比较好理解的事实,我们若通过直觉来判断,即使借住数据的帮助也仍然会出错。
这里还有另外一个例子:吸烟与肺癌的关系。如果我们从历史数据上观察,可以观察到吸烟的人更容易得肺癌,所以吸烟和肺癌是正相关。但是我们可以说是吸烟导致肺癌吗?其实这个事情是很难说的。因为可能存在一些未观测的因素,既影响个体是否吸烟,同时影响个体是否得癌症。有这样基因的人即使不吸烟,也容易得肺癌。这时我们只能说吸烟和肺癌有相关性。
我们再看一个例子:了解二战的人都知道,在二战中,参加空战的飞机很容易受损、坠机。于是美国空军做了研究,统计那些从战场上安全返回的飞机的着弹点,看飞机受伤的地方主要分布在哪里,从而在今后制造飞机时加固这些部位。这时候有个统计学家指出这个统计是不对的,因为只统计了从战场上安全返回的飞机,那些被击落的飞机根本没有参与统计。这就是统计学上非常著名的“幸存者偏差”概念。
我举了3个例子。第一个例子中,我们使用定性研究的方法,试图用数据得出结论;第二个例子中,我们使用数据研究相关关系;第三个例子中,我们收集数据作统计分布研究。在三个例子中我们都使用了数据,却都容易陷入细节的陷阱中得出错误的结论。所以光有数据不一定能得到正确的结论。
对于产品经理来说,该怎么办呢?
内功心法:玄门正宗
我的建议是我们要苦练内功,把内功练好,犯错的概率就很低。内功也有很多类型,有的是玄门正宗的内功,在练习的时候进度比较慢,但是根基特别扎实;如果一开始贪图速度快,去学旁门左道的内容,那么到了后期你犯错的概率就会高。
在数据分析里,我认为分析体系是整个的核心。说到玄门正宗的内功,我们很容易就想到电商的泰山北斗——亚马逊。关于亚马逊的传说有很多,但其实你若和亚马逊的人聊天,你会发现他们推崇的不是那些花哨的招数,而是亚马逊的“三个飞轮”:
o当我把所有商家聚集到一起,用户就有更多选择,就会产生更好的用户体验,从而带来更多流量;
o如果我们进一步降低成本的结构,让用户享受到更低成本的服务,我们又可以获得更多流量。
o如果我们进一步提高效率,让大家享受到更好的送货和交付服务,那我们就可以得到在之前基础上更好的流量。
我们可以说,分析体系就是数据分析中的到“道”,它的表达一定是很简洁的。在互联网的用户增长中间有一个著名的AARR模型,如下图:
凡是这种比较靠谱的、玄门正宗的分析体系,它的形式都很简洁,但内涵是很丰富的。比如我们拿出AARR模型中的获取用户环节进行漏斗拆解,就可以得到下面这样的结果:
分体体系不光可以把每个环节进行拆解,还可以把不同的环节进行打通。比如我们刚才提到的用户获取环节,一般只关注到用户获取,没有关注到用户的商业价值。如果可以将它和用户激活、留存联系起来,我们就可以形成一个更加全面的、从商业价值角度来考察用户获取渠道的图,如下例:
该图是猎聘的真实例子。以在线招聘业务为例,我们希望获取的用户质量高、简历佳,也希望用户主动看职位来应聘,于是我们从用户的质量和活跃度两个角度一起来看,关联到用户的商业价值,而不是只简单的看用户量。
招式:重剑无锋
数据分析的招式是千变万化的,只要内功练好了,招式就非常容易出效果。在射雕英雄传里,有一个情节让我记忆深刻。郭靖在刚刚学降龙十八掌的时候,只学了内功,招式来不及学全,只会一招“亢龙有悔”,这时候他的仇家寻上门来了,郭靖只好用一招御敌,但由于他的内功修得非常到位,所以这个简单的招式发挥了非常大的效果。
在整个招数里,我比较推崇的是在练好内功(分析体系)之后,可以用非常简单的招式来应对。在这里我推荐一个非常适合初学者使用的、效果很好的招式:
建立假设、小心验证
在有了分析体系之后,其实我们也有了一个“基线假设”。什么是基线假设呢?比如我们刚才如果使用用户获取的漏斗,那么这个漏斗的合理转化率是多少就是基线假设。在有了基线假设之后,我们在进行指标监测的时候对指标的范围就能够做到心里有数。
比如我们在分析的时候发现,用户已经点击付款了,但完成付款的转化率只有50%,那我们就会知道可能是产品有问题,或者数据统计出了错误。围绕问题我们可以进行数据探索。这其中最有价值的点在于通过数据的探索,可以发现原有的分析体系的不完备之处,这时其实是数据发挥最大价值的时候。
基于新的数据探索,我们还可以有一些大胆的新猜想,但在猜想之后还要用数据进行验证,不光是做历史数据的验证,还要进行新的实验(如A/B测试、AA测试等)进行验证。在通过验证之后得到的新假设,可以用于更新原有的分析体系,建立新的基线假设,在此基础上又可以展开新一轮的指标监测,发现新的问题。
这个招式其实看上去就一招,就是建立假设、小心验证,如此循环往复。但事实证明,这个方法是非常有用的,相比从一开始就脱离体系,去单点地找问题,它发挥作用的可能性要高得多。
我在刚到猎聘的时候 ,与C端用户的产品经理聊,发现当时有一个情况就是大家对于用户的行为有下面这样的假设:
用户访问猎聘网站的频率和周期和用户的求职周期是完全一致的,比如:一个人平均2-3年换一次工作,所以用户也会2-3年会来一次招聘网站;在互联网行业,找工作一般是1-2个月,所以我们认为活跃期一般为30天;在整个活跃期中,用户平均访问网站次数为10次。
那么这个假设对不对呢?我当时觉得这个假设还是挺靠谱的。因为它和我们实际工作中的经验比较吻合,这个假设也和当时的一些数据非常吻合。
我们当时看了2个数据,一个是用户注册30天后的活跃比例(下图),比如第一天有100个用户来了,第二天可能就再访问网站的只有70个,第三天更少,这样逐步减少到0。我们当时觉得一个用户的活跃周期是30天是基本合理的。
另一个数据是注册用户数与网站日活数进行对比(下图),这两条曲线趋势惊人的一致。
由于这些数据非常完美,我们认为我们已经掌握了用户的行为规律。但是所有的数据之间能互相验证的时候,往往也是非常危险的。果不其然,我们刚才举例的时候说的是第一个用户活跃周期,那么到了第二个用户活跃周期的时候,曲线就发生了变化。橙色线显示,新注册用户数在第二个大周期比第一个周期有所下降(因当时广告投放的成本控制所致),但是用户的活跃(蓝色线)并没有受此影响,而是显著上升的。也就是说,用户访问频率和求职周期并不相符。这就与前面的假设相矛盾了。那么原先的假设是哪里出现问题了呢?
很多时候出现问题对于数据分析师来说是一件好事,因为问题的出现往往也是数据分析的提升机会。后来我们对数据进行深入分析发现,原先基于直观经验和简单调研而对用户进行的假设,是不能够刻画所有用户的。事实上,只有大概50%多的用户是和我们的假想一致的,而小一半的用户则不然,有些用户甚至一年之中有10-12个月都会来访问招聘网站。
工具:唯快不破
数据分析要慢工出细活,要把基础打好。但是在工具方面,就一定要唯快不破了,我们要追求效率。
在当今时代,数据是最宝贵的资产,所以对于能够爬取网站数据的爬虫我们应当加以关注。那么应该怎样分析网站数据中是否有爬虫存在呢?比如说我们抓取了网站的UV和PV数据,直观上觉得有爬虫的时候,UV和PV的关系一定是有异常的。但是比如下面这张图中,要找出UV和PV异常的点,是比较困难的。
但是同样的数据,如果我们从不同尺度进行探索,就会有明显的差别:
即使是这样,我们仍然半信半疑,这些异常真的是否表明有爬虫呢?这时候我们可以再做进一步的数据探索:按小时进行观察比对。
如下图,每一根柱子代表一个小时的访问量,可以很明显地看到右侧一根黄色的柱子显示很明显,这种数据一定是有异常波动的,很可能是有一个爬虫程序在访问网站。
当我们有一个业务猜想的时候,进行探索的量可能是很大的,这时候整个探索的效率就显得很重要。对产品经理来说,一定要学会EXCEL中的透视表等工具,以及掌握一些可视化的方法。
困惑和迷思
最后我还希望与大家分享一下数据分析中常见的三个困惑。
脱离决策看数据:丧失焦点,劳而无功
我在工作中会招聘很多数据分析师,在面试的时候,我特别喜欢问一个问题:你觉得你做数据分析是为了什么?
很多人告诉我,是为了从数据中发现规律的时候的那份快乐。
这句话是没错的。但我们生活在一个数据维度爆炸的时代,在做产品相关的数据分析时,不可能把所有维度、所有问题看得那么清楚。我们做数据分析的目的是为了在研究产品的时候把重点问题找出来,排序工作的优先级,而不是搞清楚所有问题。所以我们要探索数据,但不能脱离决策去探索。
是否决策越多越快越好?
在投资领域,有一个叫作“均值回归”的概念,即当一个投资组合具有很高收益的时候,它其实也具有向下回归的趋势,即回归于平庸,反之亦然;短时间看,投资收益有高有低,但最后大家都会变得差不多。
我们在做数据分析的时候情况也是一样的。虽然我们有时候看到数据在波动,但很多波动是随机的、暂时的,并不能说按天决策、按小时决策就一定比按周决策、按月决策要好。
我们的系统是由暂态和稳态组成的,当系统处于暂态的时候,对系统施加控制往往无法达到预期,而当系统处于稳态的时候再施加控制则可能会很快达到预期。所以我们建立指标分析体系是很重要的,会有利于帮助我们判断系统是否处于临时的波动状态,如果是,则不要轻易地做运营决策,最好能等趋势比较明显和稳定之后再来决策。
公关故事中的Tricks怎么学?
现在是一个信息爆炸的时代,我相信大家从各个渠道都关注了大量的先进企业的先进经验和技巧,我们当然要学,但不用每一个都学。当我们看到炫目的技巧时,应当考虑2个问题。
首先是事件的背景是什么。很多时候网上的文章为了获得点击量只会摘取最吸引眼球的部分公布,而背后的背景则不太愿意讲。而企业的决策和其当时的背景是有很大联系的,我们应当要把决策背后的原因找出来。
第二则是我们要与故事背后的人、相关企业的员工进行沟通,从而决策我们是否真的要学习。
我们所有人都生活在大数据的时代,人人都想从数据中挖到金子,但是数据分析的道路是充满陷阱的。为了把数据分析做好,一方面要苦练内功,学习一些朴实无华的数据分析招式,同时拓展自己使用数据分析工具的能力,让数据探索更快,效率更高。
在未来,数据分析会成为产品经理必不可少的技能。无论大家现在是运营岗位还是从事产品设计,如果在数据分析上有一定基础,一定可以在让产品经理的道路越走越宽,越走越远。






