
唐刚老师: Cloudera原厂授权讲师。北航硕士,10年IT研发与培训经验,对Java、Hadoop、Scala、Spark、数据挖掘、机器学习等大数据技术具有深厚的技术功底,曾参与开发电商日志分析、广告实时推荐、金融异常交易预警、基于GPS的实时路况分析、超速频发路段监控等项目。

5、6年前,大数据的概念还不为人所知,Hadoop更是没几个人知道,唐刚老师由于工作上的因缘,幸运的成为最早接触并使用Hadoop进行大数据开发的那批人。在后来的日子,他没有像其他人那样去大公司做高管或者创业,而是慢慢走上了大数据开发的培训之路。
唐刚老师认为技术讲师是一份对人要求更高的工作,不仅要走在技术的前沿,还要善于讲解和表达。五年多来,他一直在大力推行Hadoop和Spark,但仍有不少人对这两种开发工具的运用表示困惑或带有误解。在采访中,唐刚老师结合自己的经历,探讨了Hadoop和Spark的优劣和应用,并给出了学习建议和学习路径,数据妞希望能对有志转型大数据或步入大数据行业的人有所帮助。
数据妞:能否谈谈您与Hadoop的接触经历?
唐刚:我大学读的是计算机,但那时候我对编程其实没有什么兴趣。在学校里我们学的是C语言、汇编语言等等,采用的都是DOS界面,非常枯燥。这种感觉直到接触VB才大大改变,因为VB是有可视化效果的,我才觉得原来编程也挺好玩的。后来我又接触了Java,毕业之后就一直在做Java开发。
2010年到2011年那时,我工作的公司要做一个Java Web的项目,数据量非常大,用Java去查询数据的时候速度非常慢,我们就想办法如何去解决这个问题。那段时间我在一个国外的技术网站上看到了Hadoop,我才知道原来还有这样一个东西,它可以有效提升数据处理的速度,于是我在一次公司例会上提议学习Hadoop。
那时候国内几乎没人用Hadoop,就连知道的人也很少,我们学习途径主要就通过Hadoop的官方网站。另外幸运的是,我有一个朋友当时在读研,他的研究生毕业论文就是要用Hadoop 去做的,于是我有什么问题就向这个朋友讨教。
我们大概花了半年时间才完成了转型,可以说非常吃力。一是当时学习途径很狭窄,没有中文资料,也没有什么书籍,资料匮乏,一个组件可能就要研究很长时间。二是时间少,我要在完成本职工作之后再抽时间一点一点学。不过虽然辛苦,但带给我最大的好处就是我很早就与大数据开发结缘。
数据妞:您目前的工作是什么,为何有这样的职业选择?
唐刚:目前我在光环国际担任大数据教学总监,主要工作是针对大数据开发方面的培训。
以前和我一起学习Hadoop的人现在基本都混得很不错,有不少人都在做CTO或是总监级别的了。而我是因为在2011年之前曾在一些培训机构兼职讲课,从那时候开始就渐渐喜欢上了讲课,于是我跳槽之后就去了一家IT培训公司,一边大力推广Hadoop,一边做大数据项目的研发。
我认为做技术讲师是一件高难度的工作。做技术讲师首先要懂技术,要保持自己技术的先进性,其次你要能准确、合适地进行表达,因为技术是很抽象、很枯燥、很难理解的东西,你需要用近似于“大白话”的方式去说明专业的技术问题,这个对人的提高是很大的。我现在也一直在研究前沿技术,最近我一直在研究Spark和机器学习。
数据妞:您认为是什么造成了Hadoop的流行?
唐刚:Hadoop之所以能流行主要是因为大数据对存储、处理的要求比传统数据要高得多。
由于互联网(特别是移动互联网)的发展,每天都会产生大量的数据,产生数据的渠道比之前也多了很多。这些数据通过日积月累就会变成海量的大数据。
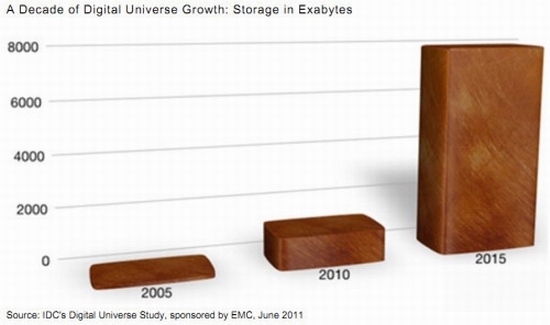
2011年全球被创建和复制的数据总量为1.8ZB(10的21次方),其中75%来自于个人,远远超过人类有史以来所有印刷材料的数据总量(200PB)。过去几年全世界产生的数据量甚至超过了历史上2万年来产生的数据量的总和。(资料来源:IDC研究报告《从混沌中提取价值》)
现在人们常说的数据挖掘、数据分析并不是新的东西,在之前已经存在很久了。但大数据时代和以前不一样,大数据如果还用以前的手段进行存储、分析是很困难的。然而Hadoop在处理海量大数据方面就非常有优势,所以可以说Hadoop是应大数据时代之势而流行起来。
Hadoop的优势主要体现在两方面:第一,它可以通过HDFS把数据进行分布式的存储,这就解决了大数据的存储问题;第二,它有MapReduce,通过编写Map函数和Reduce函数解决了大数据的计算处理问题。目前Hadoop在大数据开发领域仍然占主流。
数据妞:Spark是何时发展起来的?Spark会取代Hadoop吗?
唐刚:Spark大概是在2013年传入中国的,在2014年左右就出现了一些观点,认为Spark会取代Hadoop,或者“Spark一出,Hadoop必死”。但是我始终认为,大数据开发这个行业肯定是百家争鸣、多平台共存的行业。直到目前,我们也发现Hadoop并没有因为Spark的出现而消亡,Hadoop和 Spark都有它的优势和劣势。
从数据存储的角度来看:目前Spark生态体系中缺少一个类似于Hadoop的HDFS的子项目。HDFS(文件分布式系统)属于Hadoop生态体系的,是一个非常优秀的分布式文件系统,解决了大数据的存储问题,还有YARN平台也是一个非常优秀的资源管理系统。Spark缺少像HDFS这样一个框架,所以Spark要依赖于HDFS来进行存储。Spark在进行开发时也会用到YARN平台或者Mesos。
从数据处理速度的角度看:相比Spark,Hadoop最大的问题是处理速度慢。MapReduce产生的中间结果是放到磁盘当中的,如果我要用到Map产生的中间结果,我需要先从磁盘中读取到内存中再使用,如果又产生一个中间结果,这个中间结果又要先放到磁盘当中,再从磁盘读取到内存当中才能使用,所以说MapReduce存在无法避免的磁盘输入输出的过程,这在速度上是一个很大的缺陷。
但是Spark就不一样了。Spark处理数据所产生的中间结果放在内存中,要用的时候直接从内存读取就可以了,少了磁盘输入输出的过程,速度比Hadoop要快。
从编码的角度看:在MapReduce中,需要编写Map函数和Reduce函数,不管做什么处理,必须编写这2个函数。Hadoop的源码是Java,用Java编写MapReduce比较麻烦、繁琐,有时候代码量也挺大的。
Spark的源码是Scala,Scala写起来比较简洁,所以用Scala来开发Spark要简单得多。
Hadoop在目前大数据开发的领域仍然占主流,但是Spark的发展速度是非常快的,它是一个非常有发展潜力的框架。Hadoop更加偏向于离线批处理,Spark既可以进行离线批处理计算,也可以进行交互式计算,还可以对数据流进行准实时计算。
数据妞:国内外对Hadoop和Spark的应用情况如何?
唐刚:Hadoop、Spark的实际应用有很多。包括政府的舆情管理,例如我国的网络舆情监测系统;电信行业,例如移动、联通这样的电信运营商做精准营销(客户画像、关系链研究、实时营销和个性化推荐等);电商行业,如淘宝、天猫、京东做的个性化推荐和客户消费习惯预测;此外在教育、医疗、交通行业、农业、金融行业也有很多应用,如预防金融犯罪、预测农产品价格等等。
 图为百度交通大数据成果展中的出租车运力图(图片来源:国家测绘地理信息局)
图为百度交通大数据成果展中的出租车运力图(图片来源:国家测绘地理信息局)
国外也有不少公司在做大数据,比如Cloudera、MapR、雅虎、Facebook(推出了Hive)、推特、谷歌、IBM等等,应用也非常广泛。国内也有不少,比如BAT、京东、美团、亚信、去哪儿等。
数据妞:对于转型大数据的开发人员有哪些建议?
唐刚:对于想要转型大数据开发的IT人,有以下几点需要注意:
第一,他最好有一定的开发经历,不管做哪方面的开发,也不管是Java、.NET、PHP,至少要掌握一门编程语言。因为大数据开发肯定离不开写代码。
第二,要对数据敏感。做Java开发、Android开发更多的是强调逻辑思维,但是大数据开发不仅强调逻辑思维,还要对数字敏感。学数学或相关专业的人来做大数据是有一定先天优势的,因为他有本身经过多年的学习,对数字、数据很敏感,很适合做数据分析挖掘的工作。如果他想做大数据开发,还需要去学习一门编程语言,比如Java等等。
数据妞:假如我不会编程语言,数学功底也不好,又想从事大数据开发该怎么办?
唐刚:首先,从掌握一门编程语言开始。关于编程语言的推荐,我认为还是Java比较好。因为Hadoop目前仍然是大数据开发的主流工具,它的源码是用Java写的。而且在掌握Java之后再看Scala(Spark的源码)就比较简单了,Scala是一种函数式编程,掌握Java之后可以更好地理解函数式编程。
其次,大数据开发不需要用到很高端的数学知识,只有机器学习部分会有一些算法,这些是可以在工作当中通过项目实践来弥补的。
在职业规划上,我个人建议如果有机会就要去大公司磨练。因为大公司的技术比较前沿,接触新技术的途径也比较多,可以学到很多东西,对今后的职业生涯也有更好的保证。
数据妞:想要自学的话,有什么推荐的书籍和学习方式吗?
唐刚:可以学习的书籍太多了,比如《Hadoop权威指南》。
最好的学习途径其实就是官方网站,最好的学习资料就是官方文档,要经常去Hadoop和Spark的官网看第一手资料。虽然这两个官网都是英文的,一开始可能会让人觉得吃力,但时间长了就顺了,一方面可以学到Hadoop和Spark的技术,另一方面还可以提高英文阅读水平。
 Hadoop官网
Hadoop官网
另外还有一些学习方法也是很好的:
有问题多百度,因为你遇到的问题别人在学习当中也可能会遇到,所以有什么问题找百度;
多去一些诸如CSDN等优秀的技术网站,这些网站有很多关于大数据开发的技术资料;
多看一些技术大拿写的博客,学习他们的经验和方法,包括看他们写的代码,学习他们解决问题的思路和方法;
大数据开发始终离不开写代码,作为一名大数据开发者要多写代码,经常Coding,加深对技术的理解和熟练度;
如果公司里有大数据项目是非常好的,可以通过项目实践的方式来学习。
数据妞:深入进修Hadoop和Spark都要注意什么?
唐刚:到了大数据开发的高端领域是离不开机器学习的,开发者不仅要写代码,还要懂算法,懂算法的实现过程。Hadoop生态体系当中的Mahout 、Spark生态体系当中的MLlib都是进行数据挖掘的工具,可以把机器学习的一些算法应用到Hadoop和Spark的大数据开发当中。
现在咱们常常提到机器学习,实际上这些学科在以前早就有了,但是当时的数据量没有达到现在的级别,机器学习的作用还无法得到很好的发挥。现在进入到了大数据时代,机器学习有了更好的“用武之地”。可以说,大数据促进了机器学习。
数据妞:关于Hadoop和Spark的学习路径可否介绍一下?
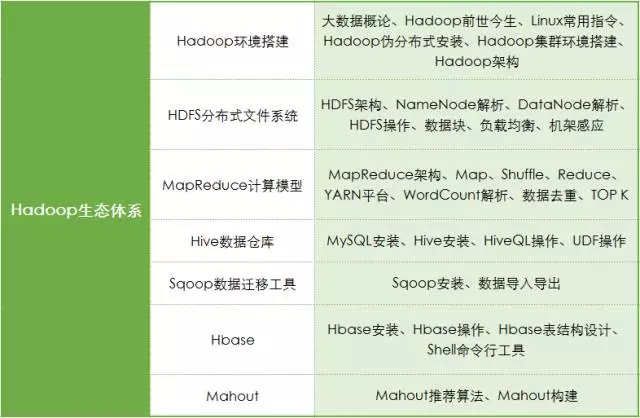
唐刚:Hadoop的一个大概的学习路径是这样的:除了搭建集群,首先要学习HDFS和YARN平台,然后是MapReduce、Hive,之后可以学习HBase,再往高级可以学习Mahout。
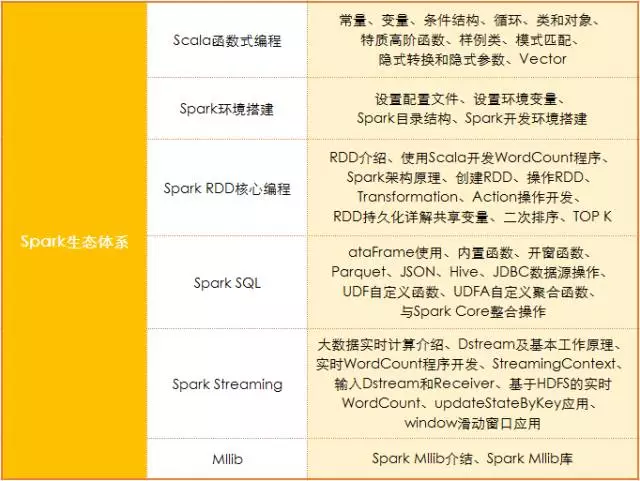
Spark除了搭建集群以外,第一个要学习RDD编程,RDD是弹性分布式数据集,然后是Spark SQL,再往下是Spark Streaming,之后是MLlib(相当于Hadoop中的Mahout),如果想再继续深入可以学习图计算GraphX。
大数据分析和数据挖掘则是另外一个方向,它用到的工具和语言有SAS、SPSS、R语言、Python。
大数据分析和大数据开发是两个方向,两套体系,现在最稀缺的还是大数据开发人员。数据分析相对来说门槛较低,而大数据开发人员要懂框架、会写代码、有数据思维、有逻辑思维,还要懂机器学习的算法,门槛就比较高,这从薪资待遇上来说也有所体现。
唐刚老师: Cloudera原厂授权讲师。北航硕士,10年IT研发与培训经验,对Java、Hadoop、Scala、Spark、数据挖掘、机器学习等大数据技术具有深厚的技术功底,曾参与开发电商日志分析、广告实时推荐、金融异常交易预警、基于GPS的实时路况分析、超速频发路段监控等项目。
5、6年前,大数据的概念还不为人所知,Hadoop更是没几个人知道,唐刚老师由于工作上的因缘,幸运的成为最早接触并使用Hadoop进行大数据开发的那批人。在后来的日子,他没有像其他人那样去大公司做高管或者创业,而是慢慢走上了大数据开发的培训之路。
唐刚老师认为技术讲师是一份对人要求更高的工作,不仅要走在技术的前沿,还要善于讲解和表达。五年多来,他一直在大力推行Hadoop和Spark,但仍有不少人对这两种开发工具的运用表示困惑或带有误解。在采访中,唐刚老师结合自己的经历,探讨了Hadoop和Spark的优劣和应用,并给出了学习建议和学习路径,数据妞希望能对有志转型大数据或步入大数据行业的人有所帮助。
数据妞:能否谈谈您与Hadoop的接触经历?
唐刚:我大学读的是计算机,但那时候我对编程其实没有什么兴趣。在学校里我们学的是C语言、汇编语言等等,采用的都是DOS界面,非常枯燥。这种感觉直到接触VB才大大改变,因为VB是有可视化效果的,我才觉得原来编程也挺好玩的。后来我又接触了Java,毕业之后就一直在做Java开发。
2010年到2011年那时,我工作的公司要做一个Java Web的项目,数据量非常大,用Java去查询数据的时候速度非常慢,我们就想办法如何去解决这个问题。那段时间我在一个国外的技术网站上看到了Hadoop,我才知道原来还有这样一个东西,它可以有效提升数据处理的速度,于是我在一次公司例会上提议学习Hadoop。
那时候国内几乎没人用Hadoop,就连知道的人也很少,我们学习途径主要就通过Hadoop的官方网站。另外幸运的是,我有一个朋友当时在读研,他的研究生毕业论文就是要用Hadoop 去做的,于是我有什么问题就向这个朋友讨教。
我们大概花了半年时间才完成了转型,可以说非常吃力。一是当时学习途径很狭窄,没有中文资料,也没有什么书籍,资料匮乏,一个组件可能就要研究很长时间。二是时间少,我要在完成本职工作之后再抽时间一点一点学。不过虽然辛苦,但带给我最大的好处就是我很早就与大数据开发结缘。
数据妞:您目前的工作是什么,为何有这样的职业选择?
唐刚:目前我在光环国际担任大数据教学总监,主要工作是针对大数据开发方面的培训。
以前和我一起学习Hadoop的人现在基本都混得很不错,有不少人都在做CTO或是总监级别的了。而我是因为在2011年之前曾在一些培训机构兼职讲课,从那时候开始就渐渐喜欢上了讲课,于是我跳槽之后就去了一家IT培训公司,一边大力推广Hadoop,一边做大数据项目的研发。
我认为做技术讲师是一件高难度的工作。做技术讲师首先要懂技术,要保持自己技术的先进性,其次你要能准确、合适地进行表达,因为技术是很抽象、很枯燥、很难理解的东西,你需要用近似于“大白话”的方式去说明专业的技术问题,这个对人的提高是很大的。我现在也一直在研究前沿技术,最近我一直在研究Spark和机器学习。
数据妞:您认为是什么造成了Hadoop的流行?
唐刚:Hadoop之所以能流行主要是因为大数据对存储、处理的要求比传统数据要高得多。
由于互联网(特别是移动互联网)的发展,每天都会产生大量的数据,产生数据的渠道比之前也多了很多。这些数据通过日积月累就会变成海量的大数据。
2011年全球被创建和复制的数据总量为1.8ZB(10的21次方),其中75%来自于个人,远远超过人类有史以来所有印刷材料的数据总量(200PB)。过去几年全世界产生的数据量甚至超过了历史上2万年来产生的数据量的总和。(资料来源:IDC研究报告《从混沌中提取价值》)
现在人们常说的数据挖掘、数据分析并不是新的东西,在之前已经存在很久了。但大数据时代和以前不一样,大数据如果还用以前的手段进行存储、分析是很困难的。然而Hadoop在处理海量大数据方面就非常有优势,所以可以说Hadoop是应大数据时代之势而流行起来。
Hadoop的优势主要体现在两方面:第一,它可以通过HDFS把数据进行分布式的存储,这就解决了大数据的存储问题;第二,它有MapReduce,通过编写Map函数和Reduce函数解决了大数据的计算处理问题。目前Hadoop在大数据开发领域仍然占主流。
数据妞:Spark是何时发展起来的?Spark会取代Hadoop吗?
唐刚:Spark大概是在2013年传入中国的,在2014年左右就出现了一些观点,认为Spark会取代Hadoop,或者“Spark一出,Hadoop必死”。但是我始终认为,大数据开发这个行业肯定是百家争鸣、多平台共存的行业。直到目前,我们也发现Hadoop并没有因为Spark的出现而消亡,Hadoop和 Spark都有它的优势和劣势。
从数据存储的角度来看:目前Spark生态体系中缺少一个类似于Hadoop的HDFS的子项目。HDFS(文件分布式系统)属于Hadoop生态体系的,是一个非常优秀的分布式文件系统,解决了大数据的存储问题,还有YARN平台也是一个非常优秀的资源管理系统。Spark缺少像HDFS这样一个框架,所以Spark要依赖于HDFS来进行存储。Spark在进行开发时也会用到YARN平台或者Mesos。
从数据处理速度的角度看:相比Spark,Hadoop最大的问题是处理速度慢。MapReduce产生的中间结果是放到磁盘当中的,如果我要用到Map产生的中间结果,我需要先从磁盘中读取到内存中再使用,如果又产生一个中间结果,这个中间结果又要先放到磁盘当中,再从磁盘读取到内存当中才能使用,所以说MapReduce存在无法避免的磁盘输入输出的过程,这在速度上是一个很大的缺陷。
但是Spark就不一样了。Spark处理数据所产生的中间结果放在内存中,要用的时候直接从内存读取就可以了,少了磁盘输入输出的过程,速度比Hadoop要快。
从编码的角度看:在MapReduce中,需要编写Map函数和Reduce函数,不管做什么处理,必须编写这2个函数。Hadoop的源码是Java,用Java编写MapReduce比较麻烦、繁琐,有时候代码量也挺大的。
Spark的源码是Scala,Scala写起来比较简洁,所以用Scala来开发Spark要简单得多。
Hadoop在目前大数据开发的领域仍然占主流,但是Spark的发展速度是非常快的,它是一个非常有发展潜力的框架。Hadoop更加偏向于离线批处理,Spark既可以进行离线批处理计算,也可以进行交互式计算,还可以对数据流进行准实时计算。
数据妞:国内外对Hadoop和Spark的应用情况如何?
唐刚:Hadoop、Spark的实际应用有很多。包括政府的舆情管理,例如我国的网络舆情监测系统;电信行业,例如移动、联通这样的电信运营商做精准营销(客户画像、关系链研究、实时营销和个性化推荐等);电商行业,如淘宝、天猫、京东做的个性化推荐和客户消费习惯预测;此外在教育、医疗、交通行业、农业、金融行业也有很多应用,如预防金融犯罪、预测农产品价格等等。
图为百度交通大数据成果展中的出租车运力图(图片来源:国家测绘地理信息局)
国外也有不少公司在做大数据,比如Cloudera、MapR、雅虎、Facebook(推出了Hive)、推特、谷歌、IBM等等,应用也非常广泛。国内也有不少,比如BAT、京东、美团、亚信、去哪儿等。
数据妞:对于转型大数据的开发人员有哪些建议?
唐刚:对于想要转型大数据开发的IT人,有以下几点需要注意:
第一,他最好有一定的开发经历,不管做哪方面的开发,也不管是Java、.NET、PHP,至少要掌握一门编程语言。因为大数据开发肯定离不开写代码。
第二,要对数据敏感。做Java开发、Android开发更多的是强调逻辑思维,但是大数据开发不仅强调逻辑思维,还要对数字敏感。学数学或相关专业的人来做大数据是有一定先天优势的,因为他有本身经过多年的学习,对数字、数据很敏感,很适合做数据分析挖掘的工作。如果他想做大数据开发,还需要去学习一门编程语言,比如Java等等。
数据妞:假如我不会编程语言,数学功底也不好,又想从事大数据开发该怎么办?
唐刚:首先,从掌握一门编程语言开始。关于编程语言的推荐,我认为还是Java比较好。因为Hadoop目前仍然是大数据开发的主流工具,它的源码是用Java写的。而且在掌握Java之后再看Scala(Spark的源码)就比较简单了,Scala是一种函数式编程,掌握Java之后可以更好地理解函数式编程。
其次,大数据开发不需要用到很高端的数学知识,只有机器学习部分会有一些算法,这些是可以在工作当中通过项目实践来弥补的。
在职业规划上,我个人建议如果有机会就要去大公司磨练。因为大公司的技术比较前沿,接触新技术的途径也比较多,可以学到很多东西,对今后的职业生涯也有更好的保证。
数据妞:想要自学的话,有什么推荐的书籍和学习方式吗?
唐刚:可以学习的书籍太多了,比如《Hadoop权威指南》。
最好的学习途径其实就是官方网站,最好的学习资料就是官方文档,要经常去Hadoop和Spark的官网看第一手资料。虽然这两个官网都是英文的,一开始可能会让人觉得吃力,但时间长了就顺了,一方面可以学到Hadoop和Spark的技术,另一方面还可以提高英文阅读水平。
Hadoop官网
另外还有一些学习方法也是很好的:
有问题多百度,因为你遇到的问题别人在学习当中也可能会遇到,所以有什么问题找百度;
多去一些诸如CSDN等优秀的技术网站,这些网站有很多关于大数据开发的技术资料;
多看一些技术大拿写的博客,学习他们的经验和方法,包括看他们写的代码,学习他们解决问题的思路和方法;
大数据开发始终离不开写代码,作为一名大数据开发者要多写代码,经常Coding,加深对技术的理解和熟练度;
如果公司里有大数据项目是非常好的,可以通过项目实践的方式来学习。
数据妞:深入进修Hadoop和Spark都要注意什么?
唐刚:到了大数据开发的高端领域是离不开机器学习的,开发者不仅要写代码,还要懂算法,懂算法的实现过程。Hadoop生态体系当中的Mahout 、Spark生态体系当中的MLlib都是进行数据挖掘的工具,可以把机器学习的一些算法应用到Hadoop和Spark的大数据开发当中。
现在咱们常常提到机器学习,实际上这些学科在以前早就有了,但是当时的数据量没有达到现在的级别,机器学习的作用还无法得到很好的发挥。现在进入到了大数据时代,机器学习有了更好的“用武之地”。可以说,大数据促进了机器学习。
数据妞:关于Hadoop和Spark的学习路径可否介绍一下?
唐刚:Hadoop的一个大概的学习路径是这样的:除了搭建集群,首先要学习HDFS和YARN平台,然后是MapReduce、Hive,之后可以学习HBase,再往高级可以学习Mahout。
Spark除了搭建集群以外,第一个要学习RDD编程,RDD是弹性分布式数据集,然后是Spark SQL,再往下是Spark Streaming,之后是MLlib(相当于Hadoop中的Mahout),如果想再继续深入可以学习图计算GraphX。
大数据分析和数据挖掘则是另外一个方向,它用到的工具和语言有SAS、SPSS、R语言、Python。
大数据分析和大数据开发是两个方向,两套体系,现在最稀缺的还是大数据开发人员。数据分析相对来说门槛较低,而大数据开发人员要懂框架、会写代码、有数据思维、有逻辑思维,还要懂机器学习的算法,门槛就比较高,这从薪资待遇上来说也有所体现。






